L’actualité ce cette rentrée 2018 apporte son flot journalier de fuite de données personnelles, d’attaques et de déconvenues dans la sphère digitale.
La relecture de l’ article du septembre 2017 sur le même sujet, pousse à aller plus loin dans la diffusion des bonnes pratiques face à l’ampleur et à la récurrence de la menace.
Cette fois ci, il s’agit de présenter un inventaire des organismes et sites de référence qui constituent une source fiable d’informations sur les moyens d’action pour se protéger.
Savoir et agir pour mettre en place une défense en profondeur, réduire sa surface « attaquable » puis évaluer en continu si les moyens de défense sont pertinents par une remise en cause de nos connaissances en matière de Cybersécurité.
La première recommandation est de se former à la sécurité des systèmes d’information.
L’agence National pour la sécurité des systèmes d’information ANSSI nous propose des MOOC* destinés à divers publics.
Plus particulièrement le cours en ligne SecNumAcademie regroupe par ailleurs tous les liens utiles vers des ressources proposées par les acteurs français en matière de lutte contre la cyber-criminalité.
Et enfin un glossaire pour bien savoir de quoi l’on parle
Suite au prochain article sur la cybersécurité qui est l’affaire de toutes et tous…
*(Un MOOC, ou Massive Open Online Course , est un cours en ligne, gratuit et accessible à tous, qui privilégie des supports diversifiés (vidéos, quizz, tests, cours, interviews, exercices, etc.)
Zeppelin est la concrétisation du concept de bloc-note interactif.
Il s’agit ici de montrer son interêt pour une utilisation collaborative de documents « motivés par les données » et pour l’analyse interactive avec SQL, Scala, Spark…
Tout d’abord, nous ne rentrerons pas dans les considérations d’installation et de documentation, je vous invite à vous référer au site officiel Zeppelin et à son contenu.
Les principaux besoins du DataScientist peuvent être couverts par Zeppelin :
Le chargement des données: Data Ingestion
La découverte et la préparation: Data Discovery
L’analyse: Data Analytics
La communication des résultats de l’analyse: Data Visualization & Collaboration
Même si Zeppelin est à l’aise dans une « architecture ouverte » et peut s’appuyer sur une large variété de moteurs d’analyse et de langages, c’est surtout son intégration avec Spark que nous allons illustrer.
Les fonctionnalités de visualisation paraîtront basiques à ceux qui maîtrisent certains logiciels experts en visualisation…
L’approche des concepteurs de Zeppelin est de donner une capacité d’interaction avec les graphiques à une large population d’utilisateurs qui ne sont pas des experts en « Dataviz ».
En permettant de matérialiser des intuitions « métiers » grâce à des vues multiples sur les data, avec un minimum d’effort d’apprentissage, on donne aux opérationnels de nouveaux leviers pour leurs plans d’action.
Ingestion
Dans ce premier exemple, on ingère un fichier de donnés compressé (.zip) en libre service à partir du site source (ici la Française des jeux).
Ce fichier est ensuite décompressé dans un répertoire local accessible par Zeppelin.
On notera que Zeppelin interprète directement les commandes shell du poste de travail sur lequel il s’exécute (ici OSX, snapshot de l’UI Zeppelin dans le navigateur Safari).
Ingestion de données open data, écriture dans l’espace local Zeppelin
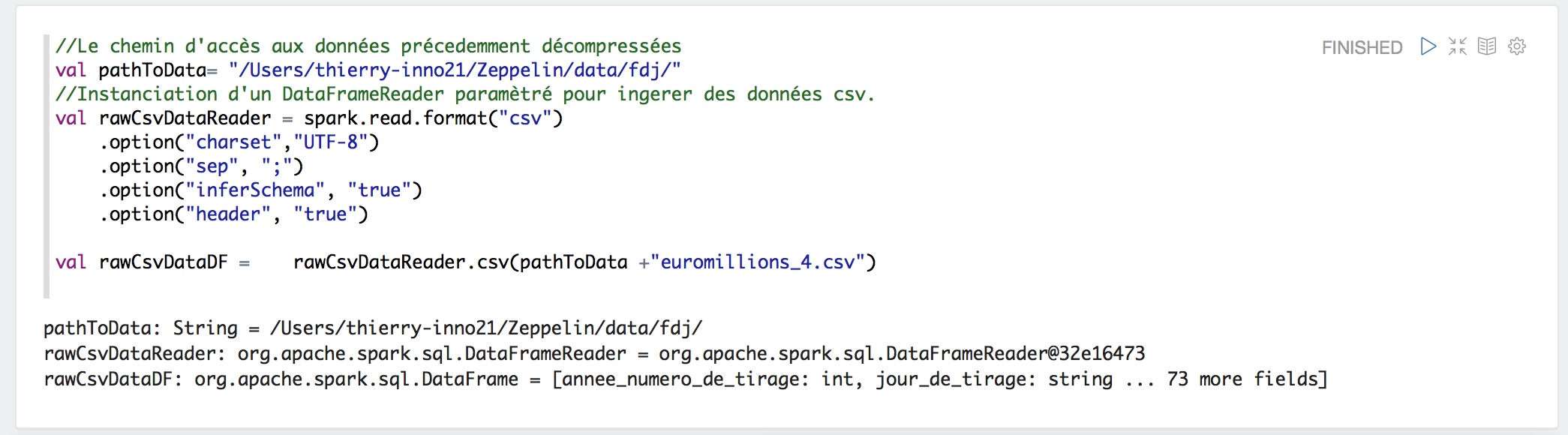
Un « reader csv » est créé avec les bons paramètres pour l’ingestion par un DataFrame Spark.
Données csv brutes lues et déposées dans un DataFrame Spark
A ce stade, le bloc Note Zeppelin accepte tout type de code Scala et Spark.
Discovery
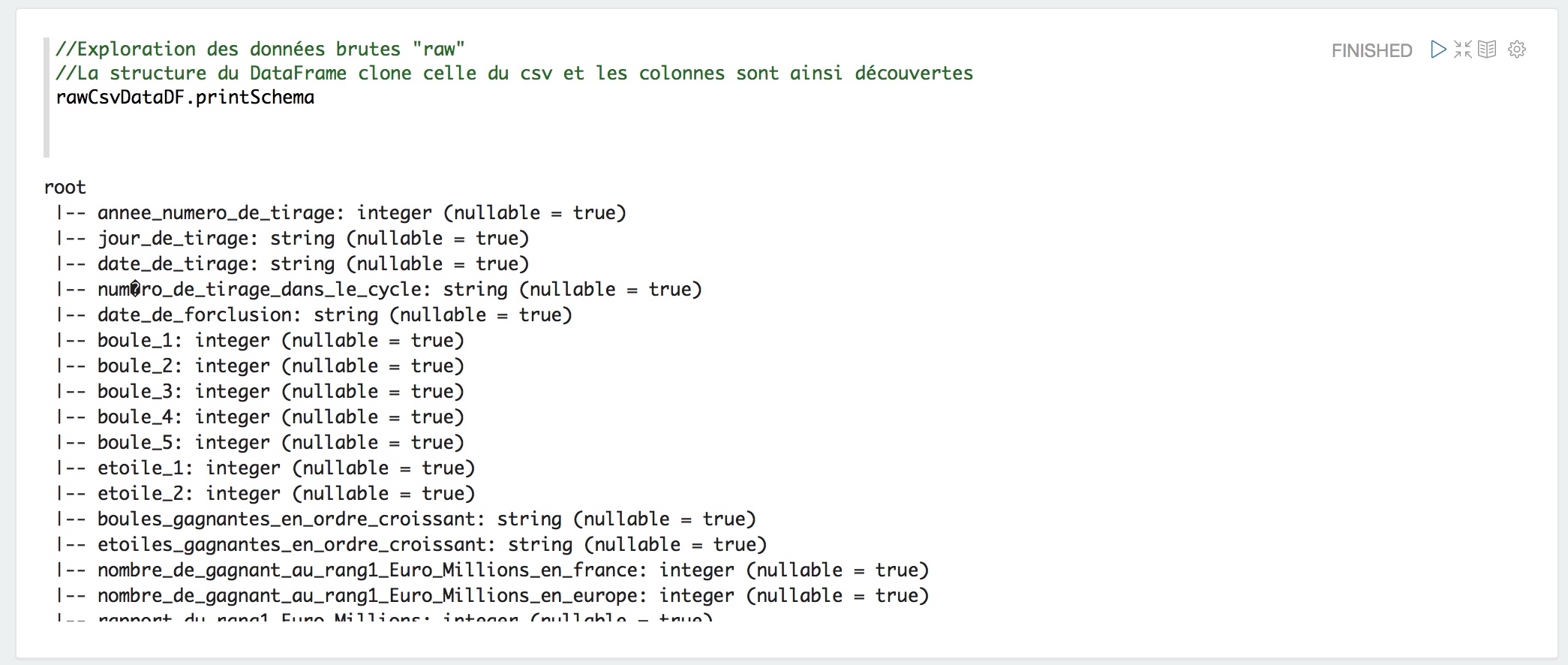
La structure de nos données open data se révèle. Nous sommes dans le cas simple où il s’agit, ni plus n’y moins, que des entêtes de colonnes de notre fichier .csv de départ.
Découverte de la structure du DataFrame
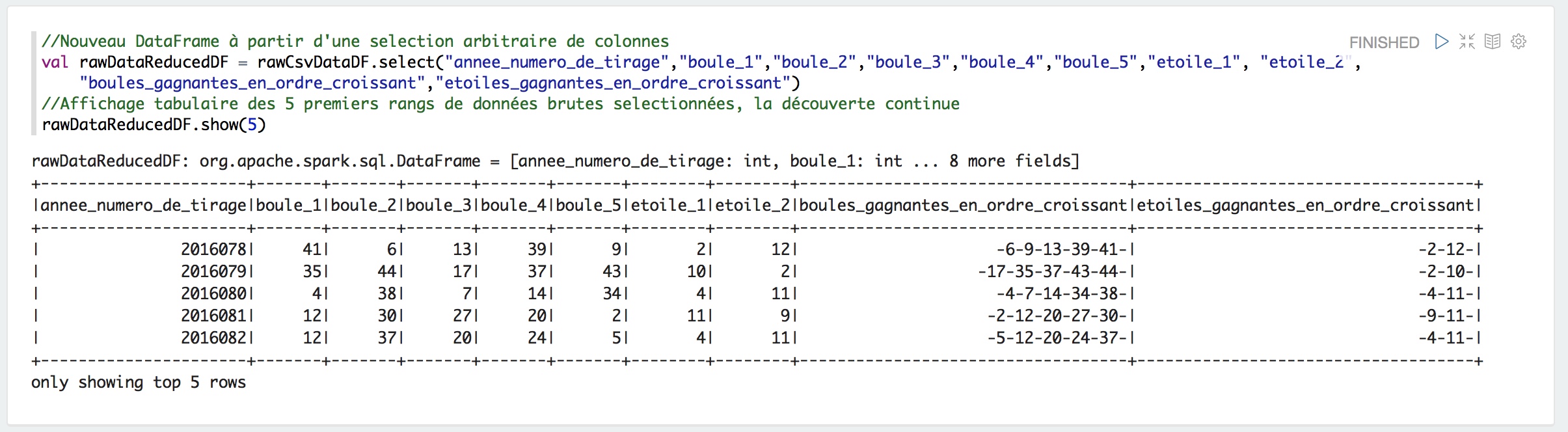
Nous sélectionnons les colonnes qui nous intéressent pour la suite et créons un nouveau DataFrame comme nouvelle étape dans la découverte et la préparation des données.
Selection des colonnes d’intérêt
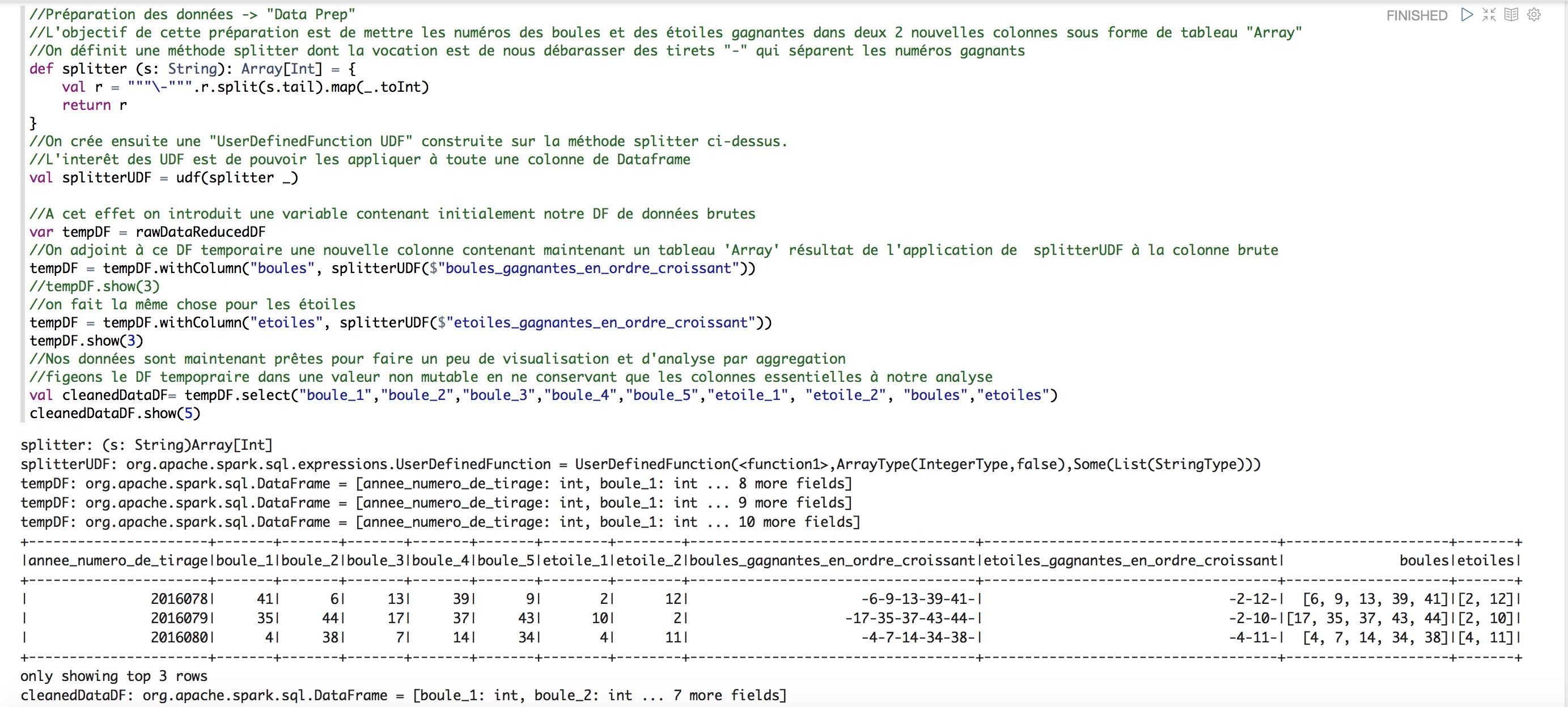
On constate que certaines colonnes contiennent des informations de type numérique (Integer) et d’autres de type chaines de caractères (String). Avant de démarrer l’analyse, il est judicieux de changer de type pour certaines colonnes. Voici un exemple pour ce genre de tactique de préparation amont.
Au préalable nous allons avoir besoin de librairies spark.sql complémentaires pour utiliser les fonctions applicables aux colonnes de DataFrame.
Importation de librairies spark.sql
Analytics
Les données étant préparées, nous pouvons commencer à utiliser Zeppelin pour l’analyse à l’aide des fonctionnalisés Spark SQL.
Le dataFrame préparé aux étapes précédentes est enregistré dans une table temporaire nommée « tirages ». Nous pouvons dès lors changer d’interprète dans les prochains paragraphes du bloc note.
Enregistrement du DataFrame au catalogue préalablement à l’analyse SQL
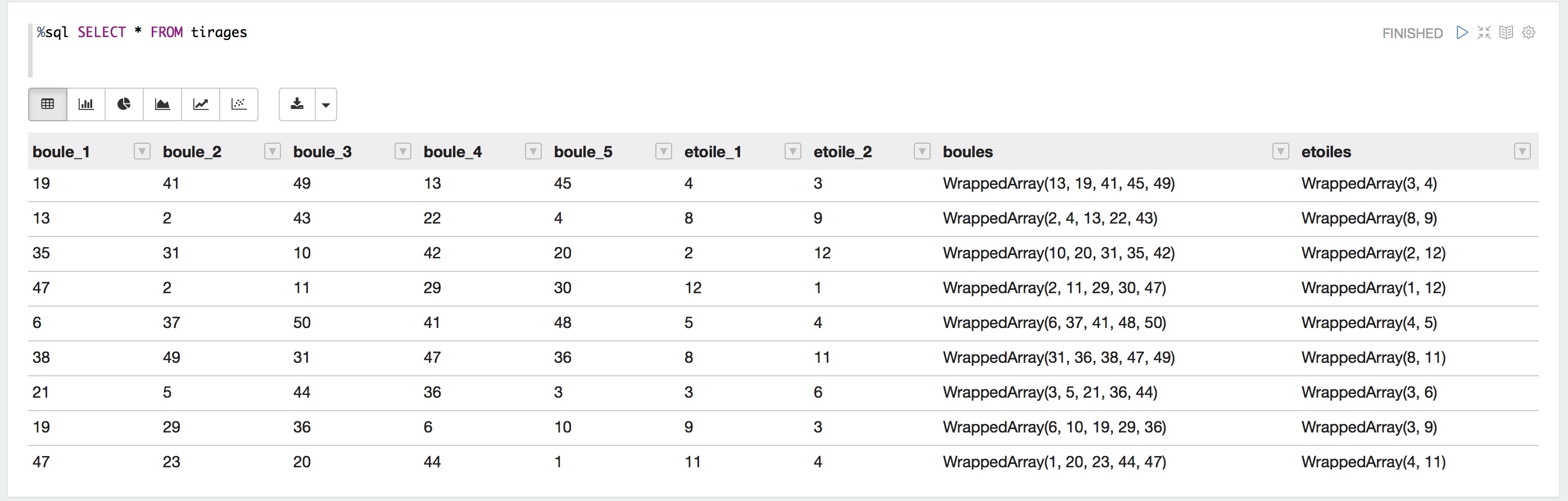
Nous visualisons à nouveau nos données préparées sous forme tabulaire.
Affichage tabulaire classique
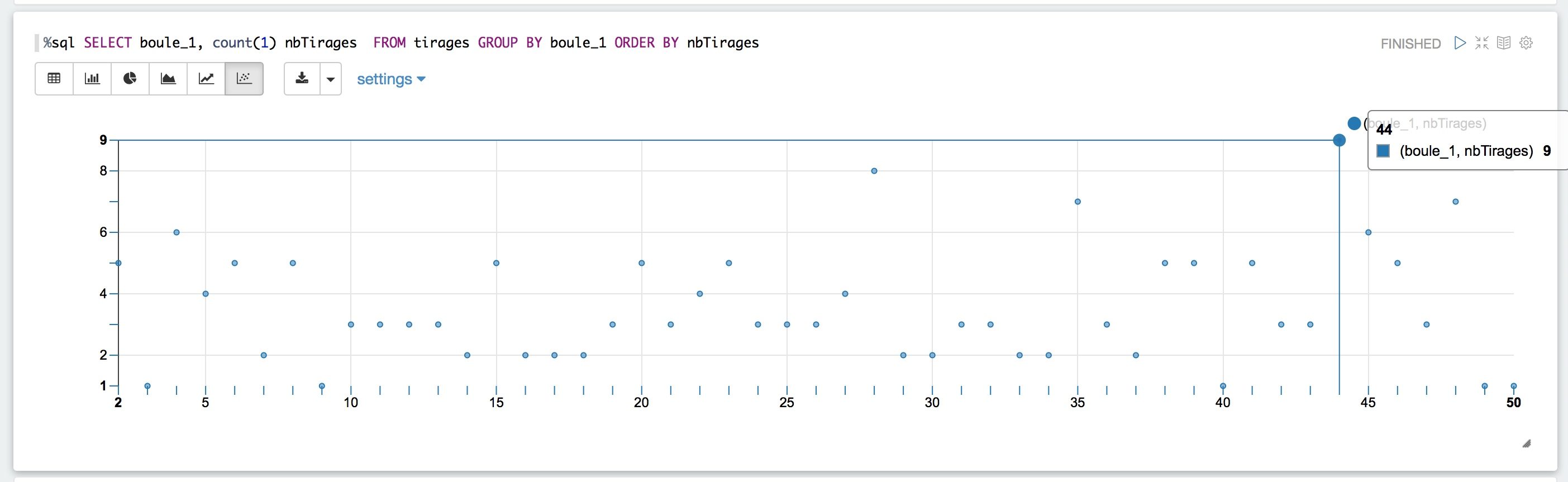
Nous pouvons par exemple nous demander : « quelle numéro est sorti le plus fréquemment lors du tirage de la première boule? »
La vue graphique interactive nous permet de répondre instantanément à la question : la boule 44 est sortie 9 fois première.
Lecture directe sur graphe interactif
disclaimer: cette analyse n’a pour but exclusif que d’illustrer les possibilités d’un outils d’analyse comme Spark intégré à Zeppelin. Chaque tirage étant indépendant dans une loterie comme Euro Millions, la réponse à la question ci dessus basée sur un historique public de tirages officiels, ne constitue en aucun cas une recommandation de jeu, ni une quelconque indication pour engager une mise réelle. http://www.joueurs-info-service.fr pour toute aide ou assistance sur la question des risques associés aux jeux de hasard.
Conclusion
Quels sont les bénéfices de Apache Zeppelin?
Les exemples simples décris dans cet articles ont mis en lumière les bénéfices suivants :
Un regroupement dans le bloc note d’outils Big Data fortement intégrés les uns aux autres
Une interface plutôt minimaliste qui facilite la prise en main
Un apprentissage rapide de type « learn by doing », avec la possibilité de modifier les lignes de code à la volée, paragraphe par paragraphe et de faire une mise au point progressive du code de traitement à partir d’examples types.
Une palette de graphiques prêt à l’emploi et facilement paramétrables
La communication collaborative des bloc notes, ainsi que la publication des paragraphes dans n’importe quelle page HTML avec une mise à jour automatique des données.
La réutilisation des traitements spécifiques pour de multiples sources de données.
La capacité de lancer des traitements tant sur un poste de travail local que sur un cluster de calcul distant de type Elastic Map Reduce d’AWS.
Apache Zeppelin est une technologie sous licence logicielle Apache2.
Alors que l’actualité nous rappelle cruellement que même un grand cabinet d’Audit n’est pas à l’abri d’une cyberattaque, cela devrait nous inciter à agir sur des reflexes essentiels dont l’objectif est de rendre la tâche plus difficile aux cyber-criminels.